Soft Performance Difference Lemma
This note presents the soft performance difference lemma, which is a fundamental result in regularized reinforcement learning. Nowadays, regularized reinforc...

Hi, I'm Hao Qin, a final-year PhD student at The University of Arizona in the program of GIDP-STATS. I am fortunate to be advised by Dr. Chicheng Zhang. Before that, I received my Bachelor's degree in Applied Mathematics from Shandong University and Master's degree in Data Science from The University of Wisconsin-Madison.
My research interests are in the field of machine learning, especially in the area of reinforcement learning. I have a particular interest in identifying the crucial factors that quantify the exploration-exploitation trade-off in reinforcement learning, which is a fundamental problem in the field. A clear understanding of this trade-off will pave the way for designing more efficient algorithms in various applications, such as recommendation systems, robotics, and autonomous driving.
Currently, I am working on the following directions:
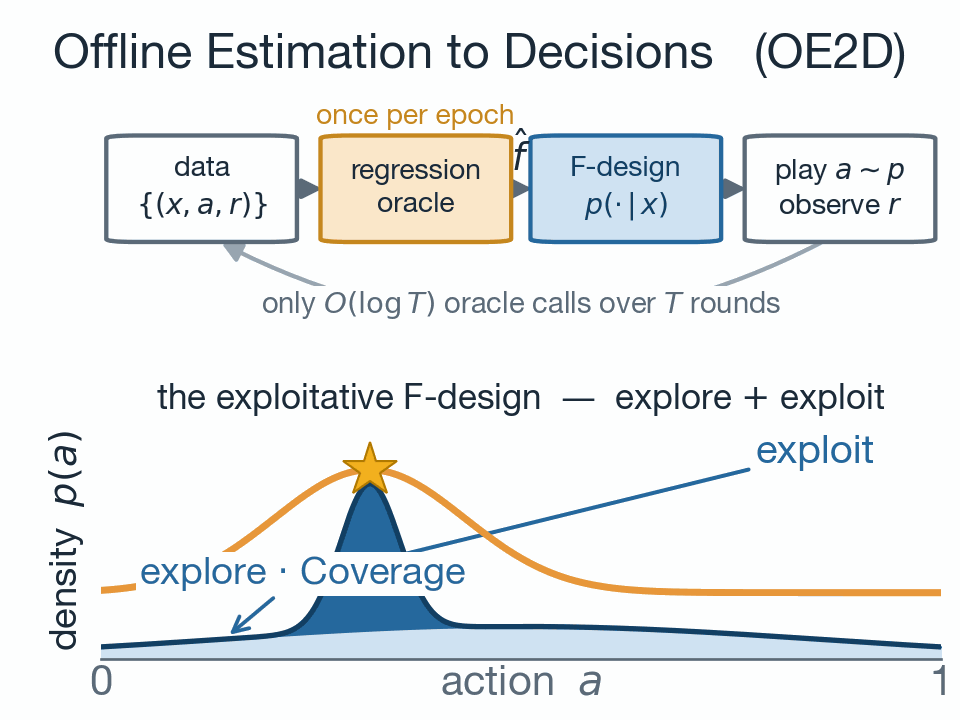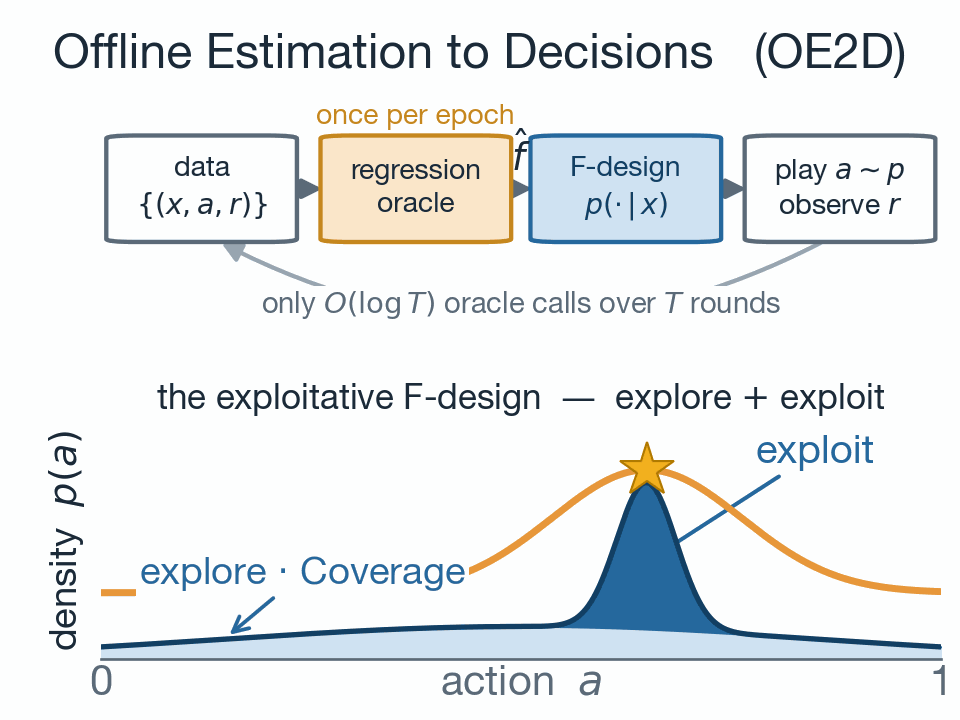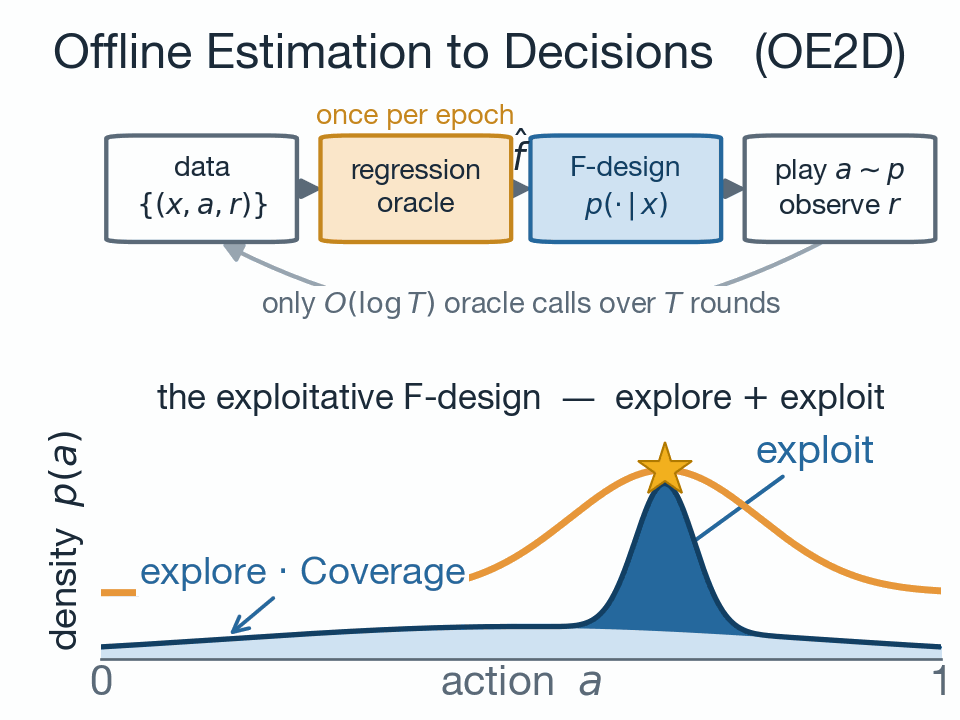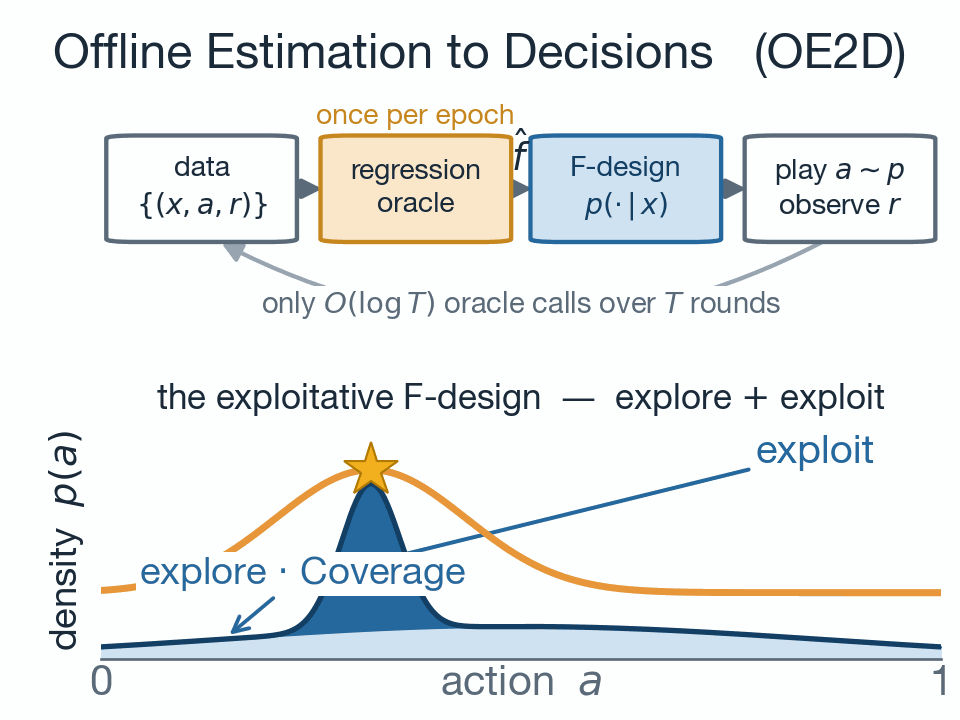
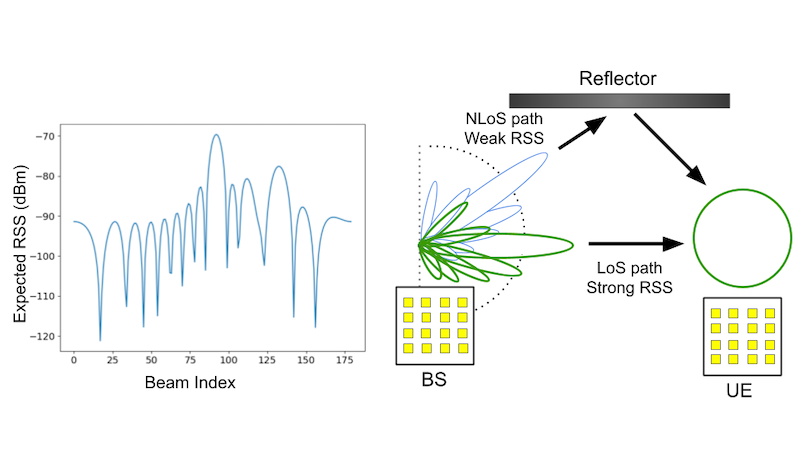

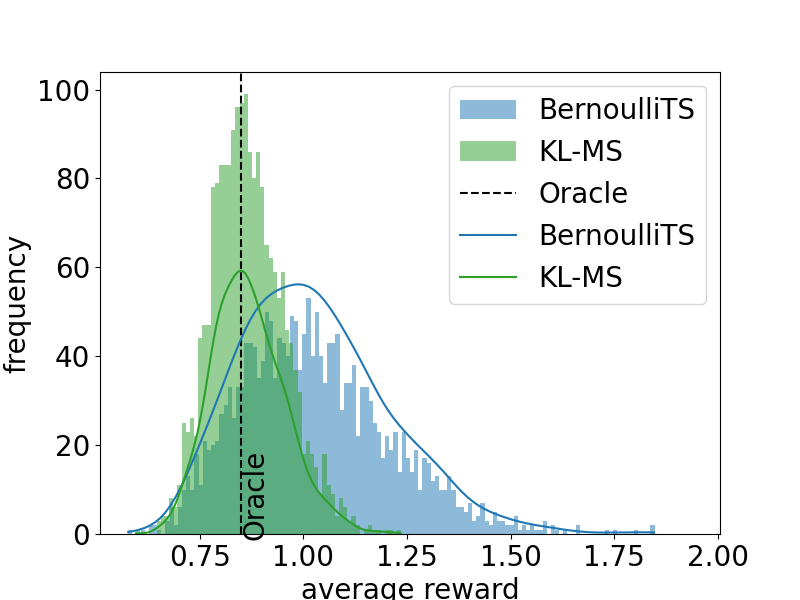
This note presents the soft performance difference lemma, which is a fundamental result in regularized reinforcement learning. Nowadays, regularized reinforc...
This is a recap of the regret analysis in (TRAVEL) Provably Efficient Learning of Transferable Rewards.
This is a recap of the “inverse bandit” problem first proposed in this paper.
This is a recap of the regret analysis in SCAL.
This is a recap of the regret analysis in UCRL2.